26 KiB
LightRAG 服务器和 Web 界面
LightRAG 服务器旨在提供 Web 界面和 API 支持。Web 界面便于文档索引、知识图谱探索和简单的 RAG 查询界面。LightRAG 服务器还提供了与 Ollama 兼容的接口,旨在将 LightRAG 模拟为 Ollama 聊天模型。这使得 AI 聊天机器人(如 Open WebUI)可以轻松访问 LightRAG。
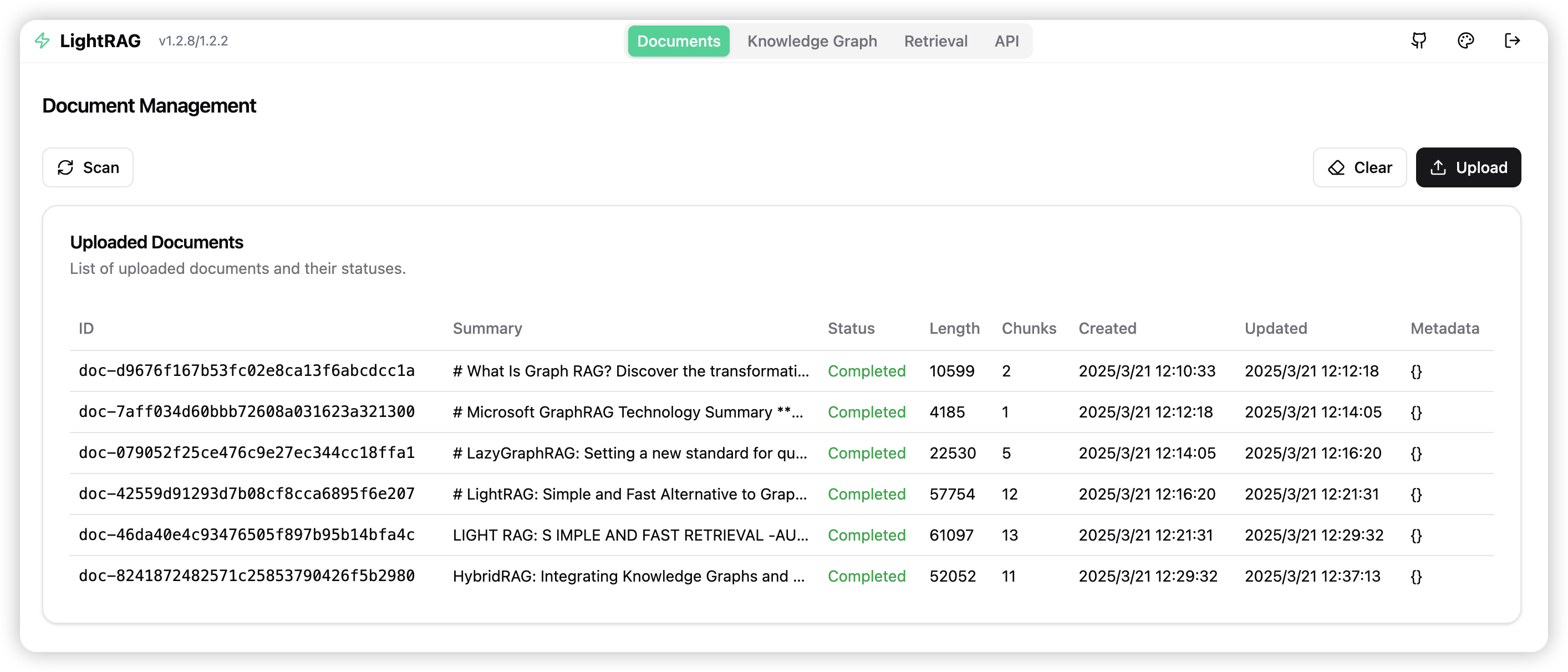
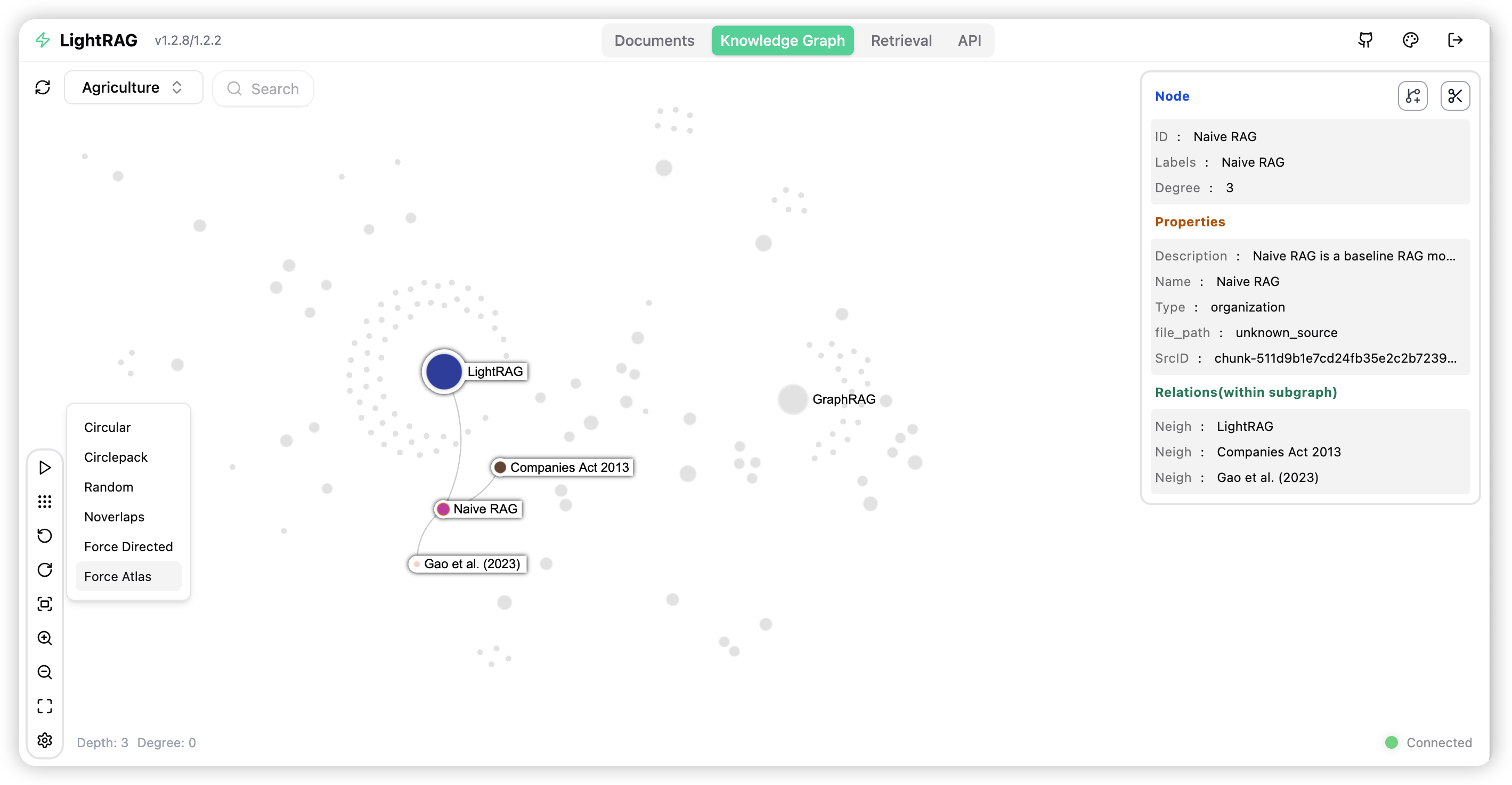

入门指南
安装
- 从 PyPI 安装
pip install "lightrag-hku[api]"
- 从源代码安装
# 克隆仓库
git clone https://github.com/HKUDS/lightrag.git
# 切换到仓库目录
cd lightrag
# 如有必要,创建 Python 虚拟环境
# 以可编辑模式安装并支持 API
pip install -e ".[api]"
启动 LightRAG 服务器前的准备
LightRAG 需要同时集成 LLM(大型语言模型)和嵌入模型以有效执行文档索引和查询操作。在首次部署 LightRAG 服务器之前,必须配置 LLM 和嵌入模型的设置。LightRAG 支持绑定到各种 LLM/嵌入后端:
- ollama
- lollms
- openai 或 openai 兼容
- azure_openai
建议使用环境变量来配置 LightRAG 服务器。项目根目录中有一个名为 env.example 的示例环境变量文件。请将此文件复制到启动目录并重命名为 .env。之后,您可以在 .env 文件中修改与 LLM 和嵌入模型相关的参数。需要注意的是,LightRAG 服务器每次启动时都会将 .env 中的环境变量加载到系统环境变量中。LightRAG 服务器会优先使用系统环境变量中的设置。
由于安装了 Python 扩展的 VS Code 可能会在集成终端中自动加载 .env 文件,请在每次修改 .env 文件后打开新的终端会话。
以下是 LLM 和嵌入模型的一些常见设置示例:
- OpenAI LLM + Ollama 嵌入
LLM_BINDING=openai
LLM_MODEL=gpt-4o
LLM_BINDING_HOST=https://api.openai.com/v1
LLM_BINDING_API_KEY=your_api_key
### 发送给 LLM 的最大 token 数(小于模型上下文大小)
MAX_TOKENS=32768
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
# EMBEDDING_BINDING_API_KEY=your_api_key
- Ollama LLM + Ollama 嵌入
LLM_BINDING=ollama
LLM_MODEL=mistral-nemo:latest
LLM_BINDING_HOST=http://localhost:11434
# LLM_BINDING_API_KEY=your_api_key
### 发送给 LLM 的最大 token 数(基于您的 Ollama 服务器容量)
MAX_TOKENS=8192
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
# EMBEDDING_BINDING_API_KEY=your_api_key
启动 LightRAG 服务器
LightRAG 服务器支持两种运行模式:
- 简单高效的 Uvicorn 模式
lightrag-server
- 多进程 Gunicorn + Uvicorn 模式(生产模式,不支持 Windows 环境)
lightrag-gunicorn --workers 4
.env 文件必须放在启动目录中。启动时,LightRAG 服务器将创建一个文档目录(默认为 ./inputs)和一个数据目录(默认为 ./rag_storage)。这允许您从不同目录启动多个 LightRAG 服务器实例,每个实例配置为监听不同的网络端口。
以下是一些常用的启动参数:
--host:服务器监听地址(默认:0.0.0.0)--port:服务器监听端口(默认:9621)--timeout:LLM 请求超时时间(默认:150 秒)--log-level:日志级别(默认:INFO)- --input-dir:指定要扫描文档的目录(默认:./input)
- 要求将.env文件置于启动目录中是经过特意设计的。 这样做的目的是支持用户同时启动多个LightRAG实例,并为不同实例配置不同的.env文件。
- 修改.env文件后,您需要重新打开终端以使新设置生效。 这是因为每次启动时,LightRAG Server会将.env文件中的环境变量加载至系统环境变量,且系统环境变量的设置具有更高优先级。
使用 Docker 启动 LightRAG 服务器
- 克隆代码仓库:
git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
-
配置 .env 文件: 通过复制示例文件
env.example创建个性化的 .env 文件,并根据实际需求设置 LLM 及 Embedding 参数。 -
通过以下命令启动 LightRAG 服务器:
docker compose up
# 如拉取了新版本,请添加 --build 重新构建
docker compose up --build
无需克隆代码而使用 Docker 部署 LightRAG 服务器
- 为 LightRAG 服务器创建工作文件夹:
mkdir lightrag
cd lightrag
-
准备 .env 文件: 通过复制 env.example 文件创建个性化的.env 文件。根据您的需求配置 LLM 和嵌入参数。
-
创建一个名为 docker-compose.yml 的 docker compose 文件:
services:
lightrag:
container_name: lightrag
image: ghcr.io/hkuds/lightrag:latest
ports:
- "${PORT:-9621}:9621"
volumes:
- ./data/rag_storage:/app/data/rag_storage
- ./data/inputs:/app/data/inputs
- ./config.ini:/app/config.ini
- ./.env:/app/.env
env_file:
- .env
restart: unless-stopped
extra_hosts:
- "host.docker.internal:host-gateway"
-
准备 .env 文件: 通过复制示例文件
env.example创建个性化的 .env 文件。根据您的需求配置 LLM 和嵌入参数。 -
使用以下命令启动 LightRAG 服务器:
docker compose up
在此获取LightRAG docker镜像历史版本: LightRAG Docker Images
启动时自动扫描
当使用 --auto-scan-at-startup 参数启动任何服务器时,系统将自动:
- 扫描输入目录中的新文件
- 为尚未在数据库中的新文档建立索引
- 使所有内容立即可用于 RAG 查询
--input-dir参数指定要扫描的输入目录。您可以从 webui 触发输入目录扫描。
Gunicorn + Uvicorn 的多工作进程
LightRAG 服务器可以在 Gunicorn + Uvicorn 预加载模式下运行。Gunicorn 的多工作进程(多进程)功能可以防止文档索引任务阻塞 RAG 查询。使用 CPU 密集型文档提取工具(如 docling)在纯 Uvicorn 模式下可能会导致整个系统被阻塞。
虽然 LightRAG 服务器使用一个工作进程来处理文档索引流程,但通过 Uvicorn 的异步任务支持,可以并行处理多个文件。文档索引速度的瓶颈主要在于 LLM。如果您的 LLM 支持高并发,您可以通过增加 LLM 的并发级别来加速文档索引。以下是几个与并发处理相关的环境变量及其默认值:
### 工作进程数,数字不大于 (2 x 核心数) + 1
WORKERS=2
### 一批中并行处理的文件数
MAX_PARALLEL_INSERT=2
# LLM 的最大并发请求数
MAX_ASYNC=4
将 Lightrag 安装为 Linux 服务
从示例文件 lightrag.service.example 创建您的服务文件 lightrag.service。修改服务文件中的 WorkingDirectory 和 ExecStart:
Description=LightRAG Ollama Service
WorkingDirectory=<lightrag 安装目录>
ExecStart=<lightrag 安装目录>/lightrag/api/lightrag-api
修改您的服务启动脚本:lightrag-api。根据需要更改 python 虚拟环境激活命令:
#!/bin/bash
# 您的 python 虚拟环境激活命令
source /home/netman/lightrag-xyj/venv/bin/activate
# 启动 lightrag api 服务器
lightrag-server
安装 LightRAG 服务。如果您的系统是 Ubuntu,以下命令将生效:
sudo cp lightrag.service /etc/systemd/system/
sudo systemctl daemon-reload
sudo systemctl start lightrag.service
sudo systemctl status lightrag.service
sudo systemctl enable lightrag.service
Ollama 模拟
我们为 LightRAG 提供了 Ollama 兼容接口,旨在将 LightRAG 模拟为 Ollama 聊天模型。这使得支持 Ollama 的 AI 聊天前端(如 Open WebUI)可以轻松访问 LightRAG。
将 Open WebUI 连接到 LightRAG
启动 lightrag-server 后,您可以在 Open WebUI 管理面板中添加 Ollama 类型的连接。然后,一个名为 lightrag:latest 的模型将出现在 Open WebUI 的模型管理界面中。用户随后可以通过聊天界面向 LightRAG 发送查询。对于这种用例,最好将 LightRAG 安装为服务。
Open WebUI 使用 LLM 来执行会话标题和会话关键词生成任务。因此,Ollama 聊天补全 API 会检测并将 OpenWebUI 会话相关请求直接转发给底层 LLM。Open WebUI 的截图:
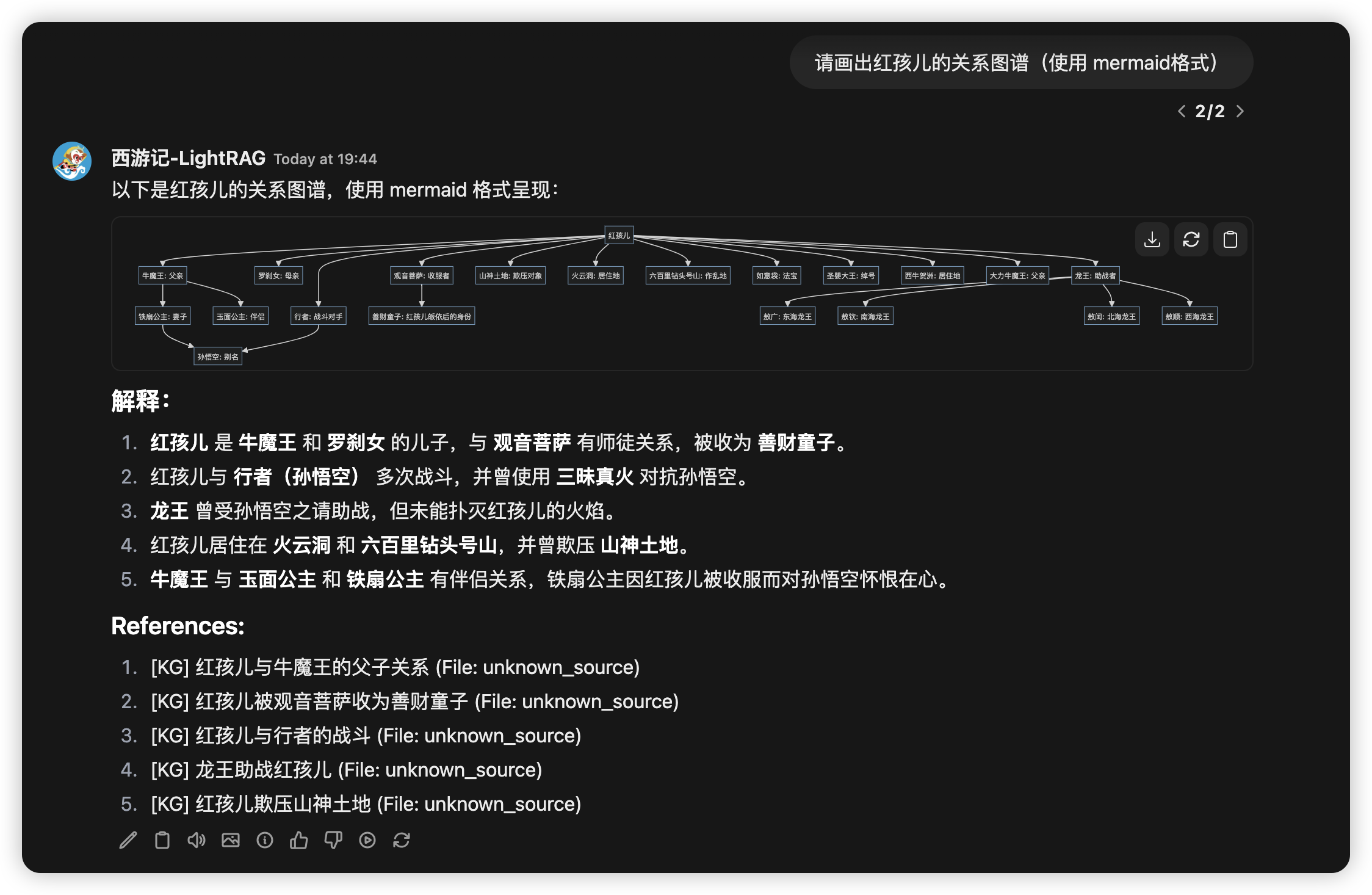
在聊天中选择查询模式
如果您从 LightRAG 的 Ollama 接口发送消息(查询),默认查询模式是 hybrid。您可以通过发送带有查询前缀的消息来选择查询模式。
查询字符串中的查询前缀可以决定使用哪种 LightRAG 查询模式来生成响应。支持的前缀包括:
/local
/global
/hybrid
/naive
/mix
/bypass
/context
/localcontext
/globalcontext
/hybridcontext
/naivecontext
/mixcontext
例如,聊天消息 "/mix 唐僧有几个徒弟" 将触发 LightRAG 的混合模式查询。没有查询前缀的聊天消息默认会触发混合模式查询。
"/bypass" 不是 LightRAG 查询模式,它会告诉 API 服务器将查询连同聊天历史直接传递给底层 LLM。因此用户可以使用 LLM 基于聊天历史回答问题。如果您使用 Open WebUI 作为前端,您可以直接切换到普通 LLM 模型,而不是使用 /bypass 前缀。
"/context" 也不是 LightRAG 查询模式,它会告诉 LightRAG 只返回为 LLM 准备的上下文信息。您可以检查上下文是否符合您的需求,或者自行处理上下文。
在聊天中添加用户提示词
使用LightRAG进行内容查询时,应避免将搜索过程与无关的输出处理相结合,这会显著影响查询效果。用户提示(user prompt)正是为解决这一问题而设计 -- 它不参与RAG检索阶段,而是在查询完成后指导大语言模型(LLM)如何处理检索结果。我们可以在查询前缀末尾添加方括号,从而向LLM传递用户提示词:
/[使用mermaid格式画图] 请画出 Scrooge 的人物关系图谱
/mix[使用mermaid格式画图] 请画出 Scrooge 的人物关系图谱
API 密钥和认证
默认情况下,LightRAG 服务器可以在没有任何认证的情况下访问。我们可以使用 API 密钥或账户凭证配置服务器以确保其安全。
- API 密钥
LIGHTRAG_API_KEY=your-secure-api-key-here
WHITELIST_PATHS=/health,/api/*
健康检查和 Ollama 模拟端点默认不进行 API 密钥检查。
- 账户凭证(Web 界面需要登录后才能访问)
LightRAG API 服务器使用基于 HS256 算法的 JWT 认证。要启用安全访问控制,需要以下环境变量:
# JWT 认证
AUTH_ACCOUNTS='admin:admin123,user1:pass456'
TOKEN_SECRET='your-key'
TOKEN_EXPIRE_HOURS=4
目前仅支持配置一个管理员账户和密码。尚未开发和实现完整的账户系统。
如果未配置账户凭证,Web 界面将以访客身份访问系统。因此,即使仅配置了 API 密钥,所有 API 仍然可以通过访客账户访问,这仍然不安全。因此,要保护 API,需要同时配置这两种认证方法。
Azure OpenAI 后端配置
可以使用以下 Azure CLI 命令创建 Azure OpenAI API(您需要先从 https://docs.microsoft.com/en-us/cli/azure/install-azure-cli 安装 Azure CLI):
# 根据需要更改资源组名称、位置和 OpenAI 资源名称
RESOURCE_GROUP_NAME=LightRAG
LOCATION=swedencentral
RESOURCE_NAME=LightRAG-OpenAI
az login
az group create --name $RESOURCE_GROUP_NAME --location $LOCATION
az cognitiveservices account create --name $RESOURCE_NAME --resource-group $RESOURCE_GROUP_NAME --kind OpenAI --sku S0 --location swedencentral
az cognitiveservices account deployment create --resource-group $RESOURCE_GROUP_NAME --model-format OpenAI --name $RESOURCE_NAME --deployment-name gpt-4o --model-name gpt-4o --model-version "2024-08-06" --sku-capacity 100 --sku-name "Standard"
az cognitiveservices account deployment create --resource-group $RESOURCE_GROUP_NAME --model-format OpenAI --name $RESOURCE_NAME --deployment-name text-embedding-3-large --model-name text-embedding-3-large --model-version "1" --sku-capacity 80 --sku-name "Standard"
az cognitiveservices account show --name $RESOURCE_NAME --resource-group $RESOURCE_GROUP_NAME --query "properties.endpoint"
az cognitiveservices account keys list --name $RESOURCE_NAME -g $RESOURCE_GROUP_NAME
最后一个命令的输出将提供 OpenAI API 的端点和密钥。您可以使用这些值在 .env 文件中设置环境变量。
# .env 中的 Azure OpenAI 配置
LLM_BINDING=azure_openai
LLM_BINDING_HOST=your-azure-endpoint
LLM_MODEL=your-model-deployment-name
LLM_BINDING_API_KEY=your-azure-api-key
### API Version可选,默认为最新版本
AZURE_OPENAI_API_VERSION=2024-08-01-preview
### 如果使用 Azure OpenAI 进行嵌入
EMBEDDING_BINDING=azure_openai
EMBEDDING_MODEL=your-embedding-deployment-name
LightRAG 服务器详细配置
API 服务器可以通过三种方式配置(优先级从高到低):
- 命令行参数
- 环境变量或 .env 文件
- Config.ini(仅用于存储配置)
大多数配置都有默认设置,详细信息请查看示例文件:.env.example。数据存储配置也可以通过 config.ini 设置。为方便起见,提供了示例文件 config.ini.example。
支持的 LLM 和嵌入后端
LightRAG 支持绑定到各种 LLM/嵌入后端:
- ollama
- lollms
- openai 和 openai 兼容
- azure_openai
使用环境变量 LLM_BINDING 或 CLI 参数 --llm-binding 选择 LLM 后端类型。使用环境变量 EMBEDDING_BINDING 或 CLI 参数 --embedding-binding 选择嵌入后端类型。
实体提取配置
- ENABLE_LLM_CACHE_FOR_EXTRACT:为实体提取启用 LLM 缓存(默认:true)
在测试环境中将 ENABLE_LLM_CACHE_FOR_EXTRACT 设置为 true 以减少 LLM 调用成本是很常见的做法。
支持的存储类型
LightRAG 使用 4 种类型的存储用于不同目的:
- KV_STORAGE:llm 响应缓存、文本块、文档信息
- VECTOR_STORAGE:实体向量、关系向量、块向量
- GRAPH_STORAGE:实体关系图
- DOC_STATUS_STORAGE:文档索引状态
每种存储类型都有几种实现:
- KV_STORAGE 支持的实现名称
JsonKVStorage JsonFile(默认)
PGKVStorage Postgres
RedisKVStorage Redis
MongoKVStorage MogonDB
- GRAPH_STORAGE 支持的实现名称
NetworkXStorage NetworkX(默认)
Neo4JStorage Neo4J
PGGraphStorage PostgreSQL with AGE plugin
在测试中Neo4j图形数据库相比PostgreSQL AGE有更好的性能表现。
- VECTOR_STORAGE 支持的实现名称
NanoVectorDBStorage NanoVector(默认)
PGVectorStorage Postgres
MilvusVectorDBStorge Milvus
ChromaVectorDBStorage Chroma
FaissVectorDBStorage Faiss
QdrantVectorDBStorage Qdrant
MongoVectorDBStorage MongoDB
- DOC_STATUS_STORAGE 支持的实现名称
JsonDocStatusStorage JsonFile(默认)
PGDocStatusStorage Postgres
MongoDocStatusStorage MongoDB
如何选择存储实现
您可以通过环境变量选择存储实现。在首次启动 API 服务器之前,您可以将以下环境变量设置为特定的存储实现名称:
LIGHTRAG_KV_STORAGE=PGKVStorage
LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
LIGHTRAG_GRAPH_STORAGE=PGGraphStorage
LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
在向 LightRAG 添加文档后,您不能更改存储实现选择。目前尚不支持从一个存储实现迁移到另一个存储实现。更多信息请阅读示例 env 文件或 config.ini 文件。
LightRag API 服务器命令行选项
| 参数 | 默认值 | 描述 |
|---|---|---|
| --host | 0.0.0.0 | 服务器主机 |
| --port | 9621 | 服务器端口 |
| --working-dir | ./rag_storage | RAG 存储的工作目录 |
| --input-dir | ./inputs | 包含输入文档的目录 |
| --max-async | 4 | 最大异步操作数 |
| --max-tokens | 32768 | 最大 token 大小 |
| --timeout | 150 | 超时时间(秒)。None 表示无限超时(不推荐) |
| --log-level | INFO | 日志级别(DEBUG、INFO、WARNING、ERROR、CRITICAL) |
| --verbose | - | 详细调试输出(True、False) |
| --key | None | 用于认证的 API 密钥。保护 lightrag 服务器免受未授权访问 |
| --ssl | False | 启用 HTTPS |
| --ssl-certfile | None | SSL 证书文件路径(如果启用 --ssl 则必需) |
| --ssl-keyfile | None | SSL 私钥文件路径(如果启用 --ssl 则必需) |
| --top-k | 50 | 要检索的 top-k 项目数;在"local"模式下对应实体,在"global"模式下对应关系。 |
| --cosine-threshold | 0.4 | 节点和关系检索的余弦阈值,与 top-k 一起控制节点和关系的检索。 |
| --llm-binding | ollama | LLM 绑定类型(lollms、ollama、openai、openai-ollama、azure_openai) |
| --embedding-binding | ollama | 嵌入绑定类型(lollms、ollama、openai、azure_openai) |
| auto-scan-at-startup | - | 扫描输入目录中的新文件并开始索引 |
.env 文件示例
### Server Configuration
# HOST=0.0.0.0
PORT=9621
WORKERS=2
### Settings for document indexing
ENABLE_LLM_CACHE_FOR_EXTRACT=true
SUMMARY_LANGUAGE=Chinese
MAX_PARALLEL_INSERT=2
### LLM Configuration (Use valid host. For local services installed with docker, you can use host.docker.internal)
TIMEOUT=200
TEMPERATURE=0.0
MAX_ASYNC=4
MAX_TOKENS=32768
LLM_BINDING=openai
LLM_MODEL=gpt-4o-mini
LLM_BINDING_HOST=https://api.openai.com/v1
LLM_BINDING_API_KEY=your-api-key
### Embedding Configuration (Use valid host. For local services installed with docker, you can use host.docker.internal)
EMBEDDING_MODEL=bge-m3:latest
EMBEDDING_DIM=1024
EMBEDDING_BINDING=ollama
EMBEDDING_BINDING_HOST=http://localhost:11434
### For JWT Auth
# AUTH_ACCOUNTS='admin:admin123,user1:pass456'
# TOKEN_SECRET=your-key-for-LightRAG-API-Server-xxx
# TOKEN_EXPIRE_HOURS=48
# LIGHTRAG_API_KEY=your-secure-api-key-here-123
# WHITELIST_PATHS=/api/*
# WHITELIST_PATHS=/health,/api/*
使用 ollama 默认本地服务器作为 llm 和嵌入后端运行 Lightrag 服务器
Ollama 是 llm 和嵌入的默认后端,因此默认情况下您可以不带参数运行 lightrag-server,将使用默认值。确保已安装 ollama 并且正在运行,且默认模型已安装在 ollama 上。
# 使用 ollama 运行 lightrag,llm 使用 mistral-nemo:latest,嵌入使用 bge-m3:latest
lightrag-server
# 使用认证密钥
lightrag-server --key my-key
使用 lollms 默认本地服务器作为 llm 和嵌入后端运行 Lightrag 服务器
# 使用 lollms 运行 lightrag,llm 使用 mistral-nemo:latest,嵌入使用 bge-m3:latest
# 在 .env 或 config.ini 中配置 LLM_BINDING=lollms 和 EMBEDDING_BINDING=lollms
lightrag-server
# 使用认证密钥
lightrag-server --key my-key
使用 openai 服务器作为 llm 和嵌入后端运行 Lightrag 服务器
# 使用 openai 运行 lightrag,llm 使用 GPT-4o-mini,嵌入使用 text-embedding-3-small
# 在 .env 或 config.ini 中配置:
# LLM_BINDING=openai
# LLM_MODEL=GPT-4o-mini
# EMBEDDING_BINDING=openai
# EMBEDDING_MODEL=text-embedding-3-small
lightrag-server
# 使用认证密钥
lightrag-server --key my-key
使用 azure openai 服务器作为 llm 和嵌入后端运行 Lightrag 服务器
# 使用 azure_openai 运行 lightrag
# 在 .env 或 config.ini 中配置:
# LLM_BINDING=azure_openai
# LLM_MODEL=your-model
# EMBEDDING_BINDING=azure_openai
# EMBEDDING_MODEL=your-embedding-model
lightrag-server
# 使用认证密钥
lightrag-server --key my-key
重要说明:
- 对于 LoLLMs:确保指定的模型已安装在您的 LoLLMs 实例中
- 对于 Ollama:确保指定的模型已安装在您的 Ollama 实例中
- 对于 OpenAI:确保您已设置 OPENAI_API_KEY 环境变量
- 对于 Azure OpenAI:按照先决条件部分所述构建和配置您的服务器
要获取任何服务器的帮助,使用 --help 标志:
lightrag-server --help
注意:如果您不需要 API 功能,可以使用以下命令安装不带 API 支持的基本包:
pip install lightrag-hku
文档和块处理逻辑说明
LightRAG 中的文档处理流程有些复杂,分为两个主要阶段:提取阶段(实体和关系提取)和合并阶段(实体和关系合并)。有两个关键参数控制流程并发性:并行处理的最大文件数(MAX_PARALLEL_INSERT)和最大并发 LLM 请求数(MAX_ASYNC)。工作流程描述如下:
MAX_PARALLEL_INSERT控制提取阶段并行处理的文件数量。MAX_ASYNC限制系统中并发 LLM 请求的总数,包括查询、提取和合并的请求。LLM 请求具有不同的优先级:查询操作优先级最高,其次是合并,然后是提取。- 在单个文件中,来自不同文本块的实体和关系提取是并发处理的,并发度由
MAX_ASYNC设置。只有在处理完MAX_ASYNC个文本块后,系统才会继续处理同一文件中的下一批文本块。 - 合并阶段仅在文件中所有文本块完成实体和关系提取后开始。当一个文件进入合并阶段时,流程允许下一个文件开始提取。
- 由于提取阶段通常比合并阶段快,因此实际并发处理的文件数可能会超过
MAX_PARALLEL_INSERT,因为此参数仅控制提取阶段的并行度。 - 为防止竞争条件,合并阶段不支持多个文件的并发处理;一次只能合并一个文件,其他文件必须在队列中等待。
- 每个文件在流程中被视为一个原子处理单元。只有当其所有文本块都完成提取和合并后,文件才会被标记为成功处理。如果在处理过程中发生任何错误,整个文件将被标记为失败,并且必须重新处理。
- 当由于错误而重新处理文件时,由于 LLM 缓存,先前处理的文本块可以快速跳过。尽管 LLM 缓存在合并阶段也会被利用,但合并顺序的不一致可能会限制其在此阶段的有效性。
- 如果在提取过程中发生错误,系统不会保留任何中间结果。如果在合并过程中发生错误,已合并的实体和关系可能会被保留;当重新处理同一文件时,重新提取的实体和关系将与现有实体和关系合并,而不会影响查询结果。
- 在合并阶段结束时,所有实体和关系数据都会在向量数据库中更新。如果此时发生错误,某些更新可能会被保留。但是,下一次处理尝试将覆盖先前结果,确保成功重新处理的文件不会影响未来查询结果的完整性。
大型文件应分割成较小的片段以启用增量处理。可以通过在 Web UI 上按“扫描”按钮来启动失败文件的重新处理。
API 端点
所有服务器(LoLLMs、Ollama、OpenAI 和 Azure OpenAI)都为 RAG 功能提供相同的 REST API 端点。当 API 服务器运行时,访问:
- Swagger UI:http://localhost:9621/docs
- ReDoc:http://localhost:9621/redoc
您可以使用提供的 curl 命令或通过 Swagger UI 界面测试 API 端点。确保:
- 启动适当的后端服务(LoLLMs、Ollama 或 OpenAI)
- 启动 RAG 服务器
- 使用文档管理端点上传一些文档
- 使用查询端点查询系统
- 如果在输入目录中放入新文件,触发文档扫描
查询端点
POST /query
使用不同搜索模式查询 RAG 系统。
curl -X POST "http://localhost:9621/query" \
-H "Content-Type: application/json" \
-d '{"query": "您的问题", "mode": "hybrid", ""}'
POST /query/stream
从 RAG 系统流式获取响应。
curl -X POST "http://localhost:9621/query/stream" \
-H "Content-Type: application/json" \
-d '{"query": "您的问题", "mode": "hybrid"}'
文档管理端点
POST /documents/text
直接将文本插入 RAG 系统。
curl -X POST "http://localhost:9621/documents/text" \
-H "Content-Type: application/json" \
-d '{"text": "您的文本内容", "description": "可选描述"}'
POST /documents/file
向 RAG 系统上传单个文件。
curl -X POST "http://localhost:9621/documents/file" \
-F "file=@/path/to/your/document.txt" \
-F "description=可选描述"
POST /documents/batch
一次上传多个文件。
curl -X POST "http://localhost:9621/documents/batch" \
-F "files=@/path/to/doc1.txt" \
-F "files=@/path/to/doc2.txt"
POST /documents/scan
触发输入目录中新文件的文档扫描。
curl -X POST "http://localhost:9621/documents/scan" --max-time 1800
根据所有新文件的预计索引时间调整 max-time。
DELETE /documents
从 RAG 系统中清除所有文档。
curl -X DELETE "http://localhost:9621/documents"
Ollama 模拟端点
GET /api/version
获取 Ollama 版本信息。
curl http://localhost:9621/api/version
GET /api/tags
获取 Ollama 可用模型。
curl http://localhost:9621/api/tags
POST /api/chat
处理聊天补全请求。通过根据查询前缀选择查询模式将用户查询路由到 LightRAG。检测并将 OpenWebUI 会话相关请求(用于元数据生成任务)直接转发给底层 LLM。
curl -N -X POST http://localhost:9621/api/chat -H "Content-Type: application/json" -d \
'{"model":"lightrag:latest","messages":[{"role":"user","content":"猪八戒是谁"}],"stream":true}'
有关 Ollama API 的更多信息,请访问:Ollama API 文档
POST /api/generate
处理生成补全请求。为了兼容性目的,该请求不由 LightRAG 处理,而是由底层 LLM 模型处理。
实用工具端点
GET /health
检查服务器健康状况和配置。
curl "http://localhost:9621/health"